1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
| import requests
import json
import re
import hashlib
import csv
import time
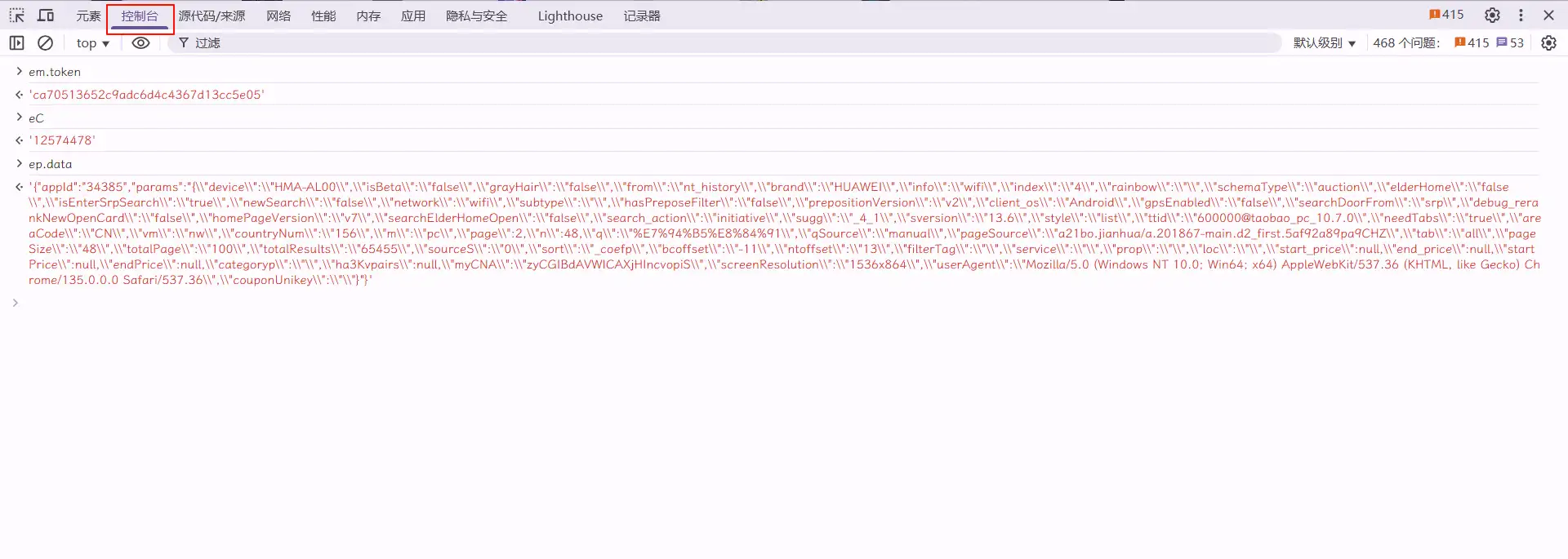
'''Sign加密逆向分析
eE(em.token + "&" + eT + "&" + eC + "&" + ep.data)
eT--时间戳, eC--appKey
'''
def getSign(eT, page, totalResults, sourceS, bc_offset, nt_offset):
em_token = 'bd25aec960a5af5dae87a57bd23a76fe'
eC = '12574478'
sign_params = {
"device": "HMA - AL00 ",
"isBeta": "false",
"grayHair": "false",
"from": "nt_history",
"brand": "HUAWEI",
"info": "wifi",
"index": "4",
"rainbow": "",
"schemaType": "auction",
"elderHome": "false",
"isEnterSrpSearch": "true",
"newSearch": "false",
"network": "wifi",
"subtype": "",
"hasPreposeFilter": "false",
"prepositionVersion": "v2",
"client_os": "Android ",
"gpsEnabled":"false",
"searchDoorFrom": "srp",
"debug_rerankNewOpenCard": "false",
"homePageVersion": "v7",
"searchElderHomeOpen": "false",
"search_action": "initiative",
"sugg": "_4_1",
"sversion": "13.6",
"style": "list",
"ttid": "600000@taobao_pc_10.7.0",
"needTabs": "true",
"areaCode": "CN",
"vm": "nw",
"countryNum": "156",
"m": "pc",
"page": page,
"n": 48,
"q": "%E7%94%B5%E8%84%91",
"qSource": "url",
"pageSource": "a21bo.jianhua/a.201867-main.d2_first.5af92a89INtItN",
"tab": "all",
"pageSize": "48",
"totalPage": "100",
"totalResults": totalResults,
"sourceS": sourceS,
"sort": "_coefp",
"bcoffset": bc_offset,
"ntoffset": nt_offset,
"filterTag": "",
"service": "",
"prop": "",
"loc": "",
"start_price": None,
"end_price": None,
"startPrice": None,
"endPrice": None,
"categoryp": "",
"ha3Kvpairs": None,
"myCNA": "zyCGIBdAVWICAXjHIncvopiS",
"screenResolution": "1536x864",
"userAgent": "Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36",
"couponUnikey": ""
}
info_data = {
'appId': '34385',
'params': json.dumps(sign_params)
}
ep_data = json.dumps(info_data).replace(' ', '')
aim_str = em_token + '&' + str(eT) + '&' + eC + '&' + ep_data
md5 = hashlib.md5()
md5.update(aim_str.encode('utf-8'))
sign = md5.hexdigest()
return sign, ep_data
'''获取下一页的参数内容
'''
def getNextParams(json_data):
totalResults = json_data['data']['mainInfo']['totalResults']
sourceS = json_data['data']['mainInfo']['sourceS']
bc_offset = json_data['data']['mainInfo']['bcoffset']
nt_offset = json_data['data']['mainInfo']['ntoffset']
return totalResults, sourceS, bc_offset, nt_offset
headers = {
'cookie': 'cna=zyCGIBdAVWICAXjHIncvopiS; thw=cn; t=b218f49912339b0ceae556e0090e211b; xlly_s=1; _tb_token_=7a5b15963ff84; cookie2=16651aea2c313a912b01cb164e4e08a0; 3PcFlag=1744784663786; _hvn_lgc_=0; cookie3_bak=16651aea2c313a912b01cb164e4e08a0; unb=3971315337; lgc=%5Cu4E00%5Cu8F6E%5Cu5F2F%5Cu6708%5Cu4E00%5Cu7F15%5Cu76F8%5Cu601D; cancelledSubSites=empty; env_bak=FM%2Bgnk3pmwgJGNrZ6%2FSkIJoxCwTm6VI1qZ6TClrxgOc3; cookie17=UNkwcc4KQQFHcg%3D%3D; dnk=hoi3vel; tracknick=%5Cu4E00%5Cu8F6E%5Cu5F2F%5Cu6708%5Cu4E00%5Cu7F15%5Cu76F8%5Cu601D; _l_g_=Ug%3D%3D; sg=%E6%80%9D74; _nk_=%5Cu4E00%5Cu8F6E%5Cu5F2F%5Cu6708%5Cu4E00%5Cu7F15%5Cu76F8%5Cu601D; cookie1=U%2BIlWIeHLSADvBxDCm0kQKQsca6SNqfz%2FIpTHfq3ZQw%3D; sgcookie=E1003OSkTgC9VlYpf2%2FnITYkh7VA%2BCuHtM4rpO%2B0DYpiEHhSZi8%2B46SUAIXRls1C9TuK6mE77ohQhH3D7Vr1b4um%2BPEe%2BqJJGCi4WxE%2BQnQE0fQ%3D; havana_lgc2_0=eyJoaWQiOjM5NzEzMTUzMzcsInNnIjoiYWU2MzZmZDI5YjQ2MDNlNGUxMGU1YTkyYThhNjYyOTEiLCJzaXRlIjowLCJ0b2tlbiI6IjFjUWNFWDNhWm9oMl9BMHFTMzRtNUhnIn0; havana_lgc_exp=1775888706045; cookie3_bak_exp=1745043906045; wk_cookie2=1b3ee28d98c093084dd38ee1285362b2; wk_unb=UNkwcc4KQQFHcg%3D%3D; uc1=cookie16=U%2BGCWk%2F74Mx5tgzv3dWpnhjPaQ%3D%3D&pas=0&cookie14=UoYaj4%2Bx2t0h1w%3D%3D&existShop=false&cookie15=V32FPkk%2Fw0dUvg%3D%3D&cookie21=URm48syIYB3rzvI4Dim4; sn=; uc3=id2=UNkwcc4KQQFHcg%3D%3D&nk2=saDbd13P348Tq%2FXU0Jk%2FOg%3D%3D&vt3=F8dD2EuMY7YkvXA3Qzs%3D&lg2=VT5L2FSpMGV7TQ%3D%3D; csg=b9bc66e6; skt=ce2a91bede66482d; existShop=MTc0NDc4NDcwNg%3D%3D; uc4=nk4=0%40s8Wb7PJZDAD5%2BPfdt88U4O4L5YsttBggT1RI&id4=0%40Ug46vpy6gA%2FUJ82j39S%2FC20NcRKR; _cc_=VFC%2FuZ9ajQ%3D%3D; _samesite_flag_=true; havana_sdkSilent=1744958760754; sdkSilent=1744970016688; mtop_partitioned_detect=1; _m_h5_tk=bd25aec960a5af5dae87a57bd23a76fe_1744909656357; _m_h5_tk_enc=ffb07dba49e6d2242032897636cd438c; tfstk=gGwrwi1R4TBPOMu-Z-Me_JQFb_H-Bv71UJgIxkqnV40oPkmnLr4C24ZhyyyEokF52X_JY3e47p95y_EHLvMh5N61CuESpvbsLYD804nLm2jjZUroe3Dh5N6XGncRPv4CcYla3Imto0mnqXjqnDmiKLcu-qcmjcToKy4nmjmIj30nZvcDiqnnK24nKikmkDMn-jUK-V9qbbjImYz_o14iaVqoudrY30Dewu02Kp24gbuMCqJHK-oucQngid5IS53S12zchLkUmDzq177wUyr3XWc4LUj7SrVU-mFA8BuatuNTtjSlEokrzjo7lhAqUW48LbFyvGEmErFtWbfAkmy7CXutgEbucouo_Wz5kp07_o4q1-TXCAVTuJliIg8JJm4GYJFy-BloDmu10ir891NT8FfC5BdKwSnq5gIJ9BhoDmu10iRp9bHx0VsR2; isg=BEJCPyO0nhwnFY2-jgYMqgg3k0ikE0YtYJe0OYxbdrVg3-JZdKCMPZIZj9ujiL7F',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36'
}
url = 'https://h5api.m.taobao.com/h5/mtop.relationrecommend.wirelessrecommend.recommend/2.0/?'
eT = int(time.time() * 1000)
page = 1
totalResults = 4800
sourceS = '0'
bc_offset = '""'
nt_offset = '""'
file = open('C:/Users/Yam/Desktop/Computer.csv', mode='w', encoding='UTF-8-SIG', newline='')
csv_writer = csv.DictWriter(file, fieldnames=['title', 'price', 'real_sale', 'procity', 'store', 'detail'])
csv_writer.writeheader()
for i in range(25):
print(f'第{i+1}次爬取...')
page = i + 1
sign, ep_data = getSign(eT, page, totalResults, sourceS, bc_offset, nt_offset)
url_params = {
'jsv': '2.7.4',
'appKey': '12574478',
't': str(eT),
'sign': sign,
'api': 'mtop.relationrecommend.wirelessrecommend.recommend',
'v': '2.0',
'type': 'jsonp',
'dataType': 'jsonp',
'callback': 'mtopjsonp5',
'data': ep_data,
}
response = requests.get(url=url, params=url_params, headers=headers)
goods_info = response.text
json_str = re.findall('mtopjsonp\d+\((.*)', goods_info)[0][:-1]
json_data = json.loads(json_str)
itemsArray = json_data['data']['itemsArray']
for item in itemsArray:
if 'title' not in item.keys():
continue
dit = {
'title': item['title'].replace('<span class=H>', '').replace('</span>', ''),
'price': item['price'],
'real_sale': item['realSales'],
'procity': item['procity'],
'store': item['shopInfo']['title'],
'detail': 'https:' + item['auctionURL']
}
csv_writer.writerow(dit)
totalResults, sourceS, bc_offset, nt_offset = getNextParams(json_data)
time.sleep(30)
print(f'第{i+1}次爬取成功!!!')
file.close()
|
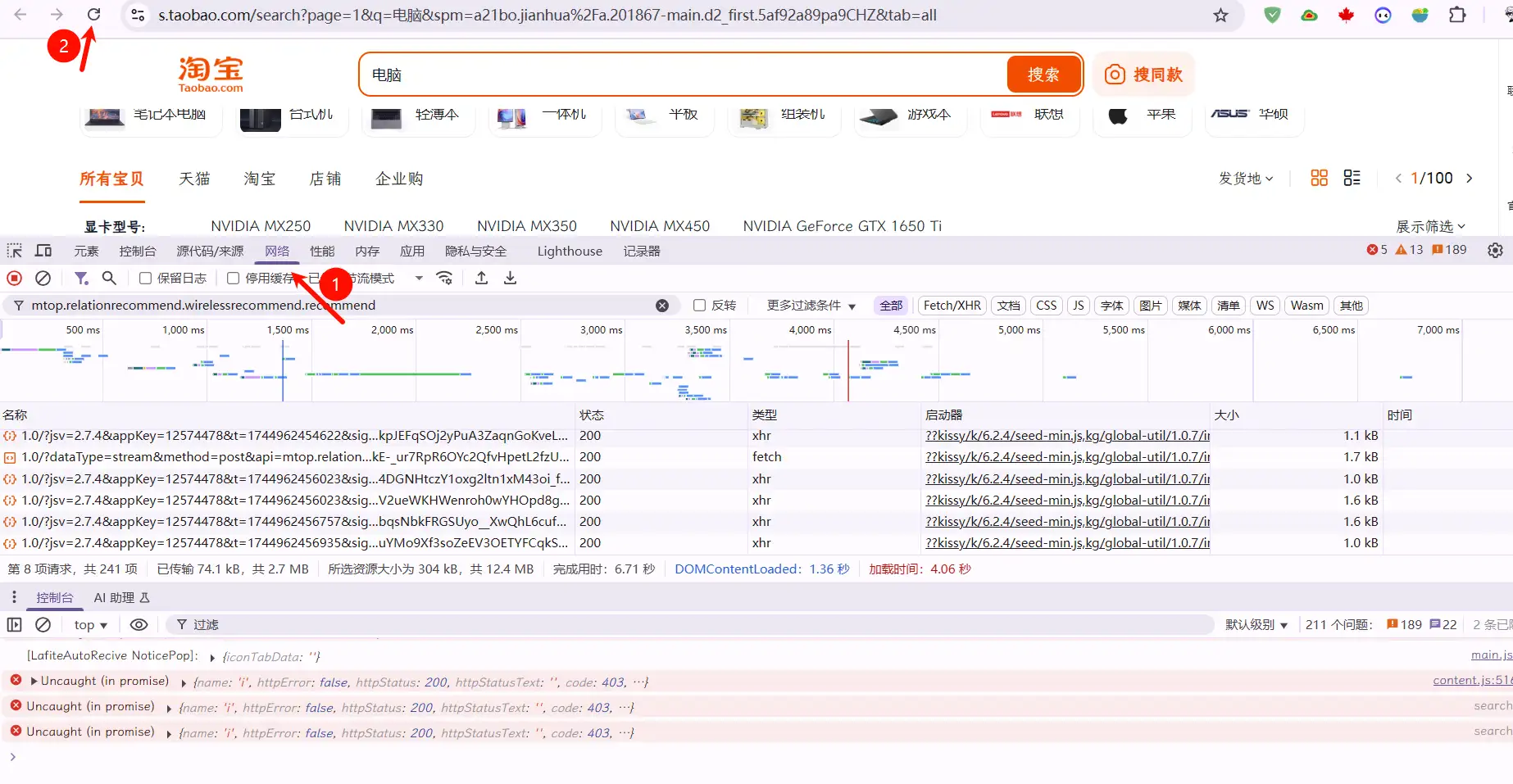
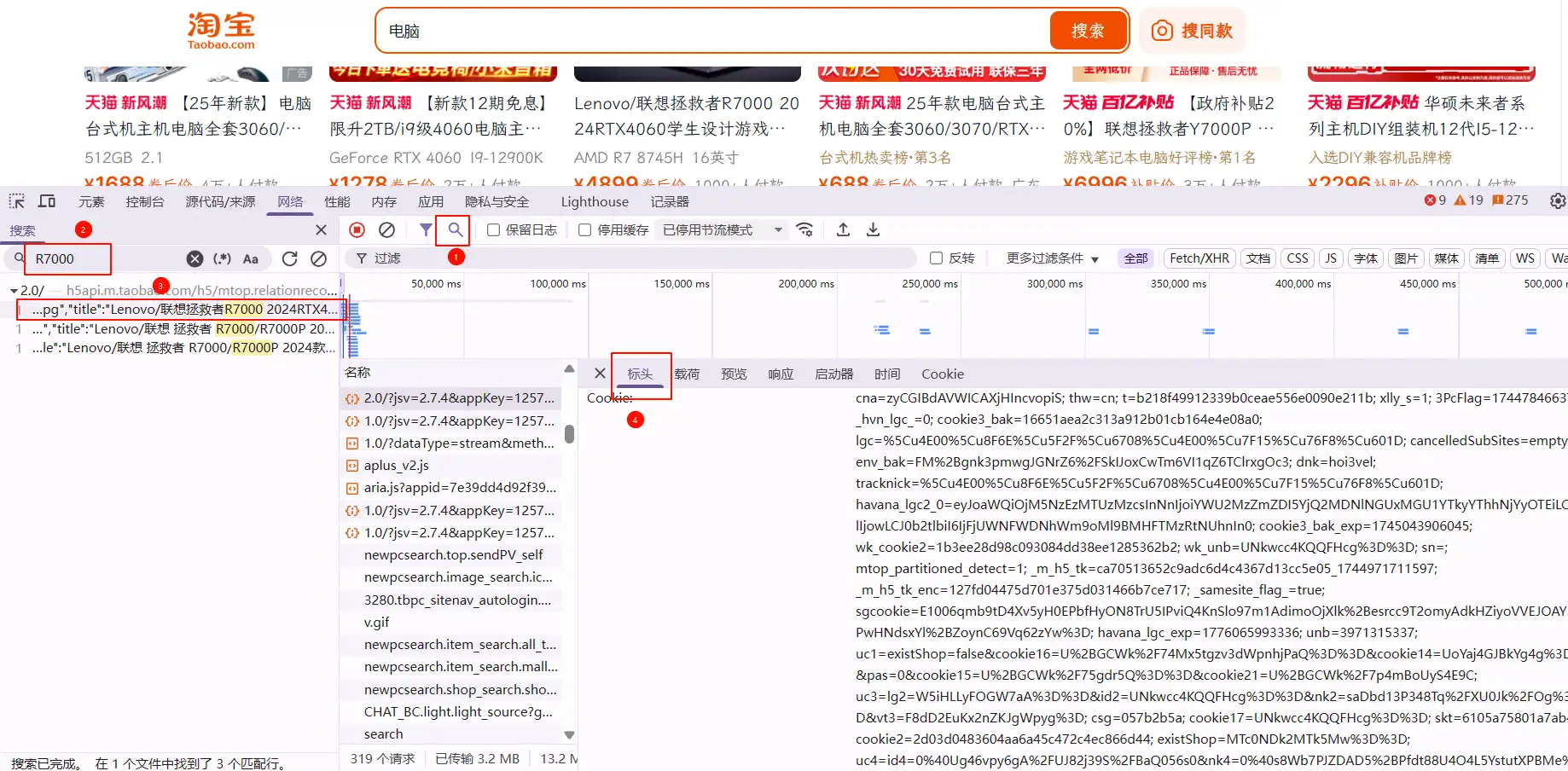
 在上图中,序号2地址即为完整数据包请求地址,序号1即为不带参数的数据包请求地址,此时需要额外构建查询请求参数。查询参数可在开发者工具中载荷页面查看,如图:
在上图中,序号2地址即为完整数据包请求地址,序号1即为不带参数的数据包请求地址,此时需要额外构建查询请求参数。查询参数可在开发者工具中载荷页面查看,如图: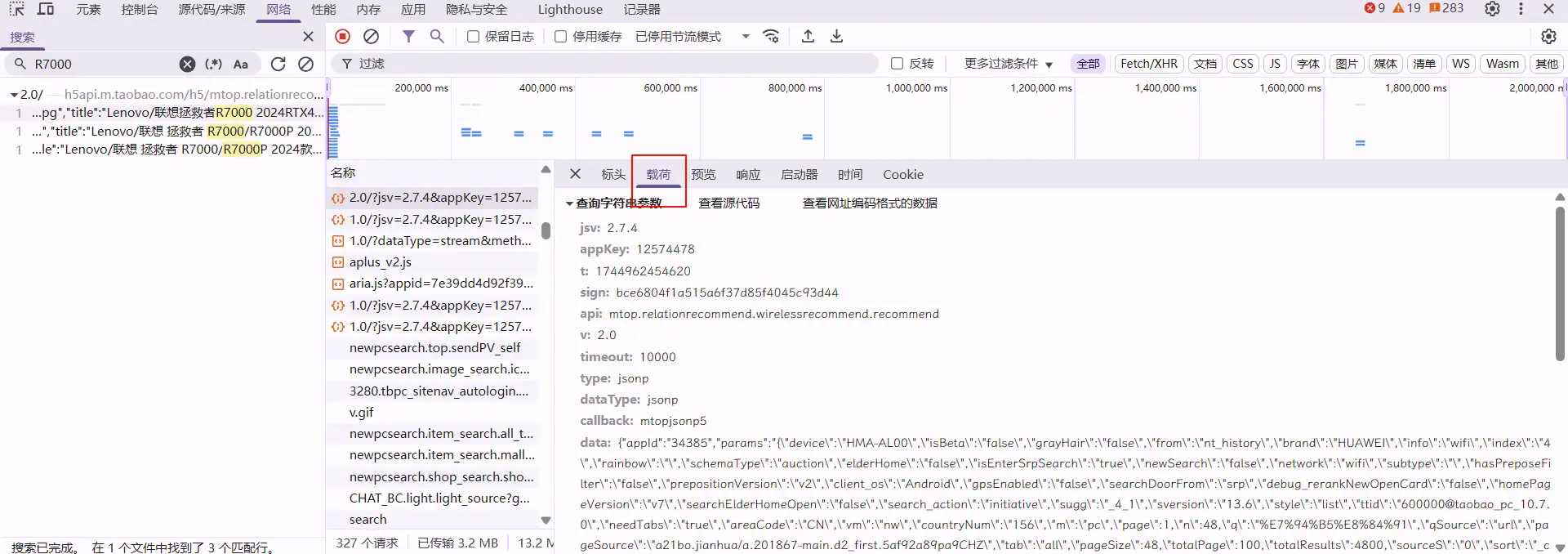
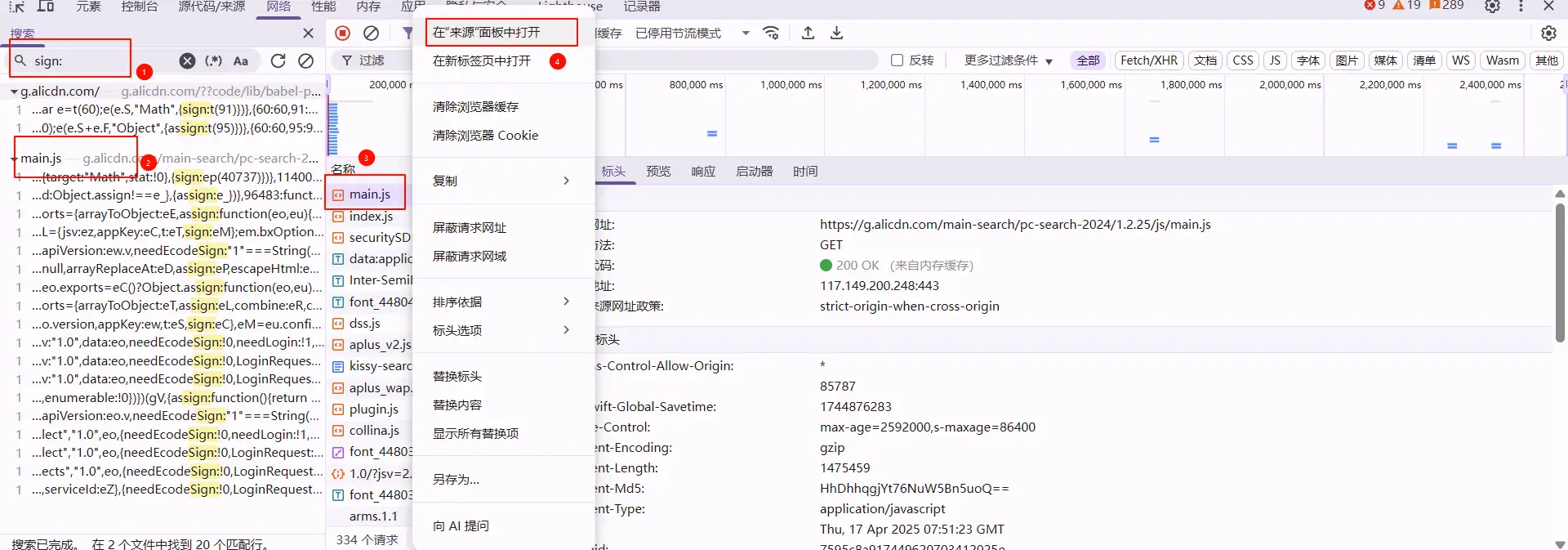
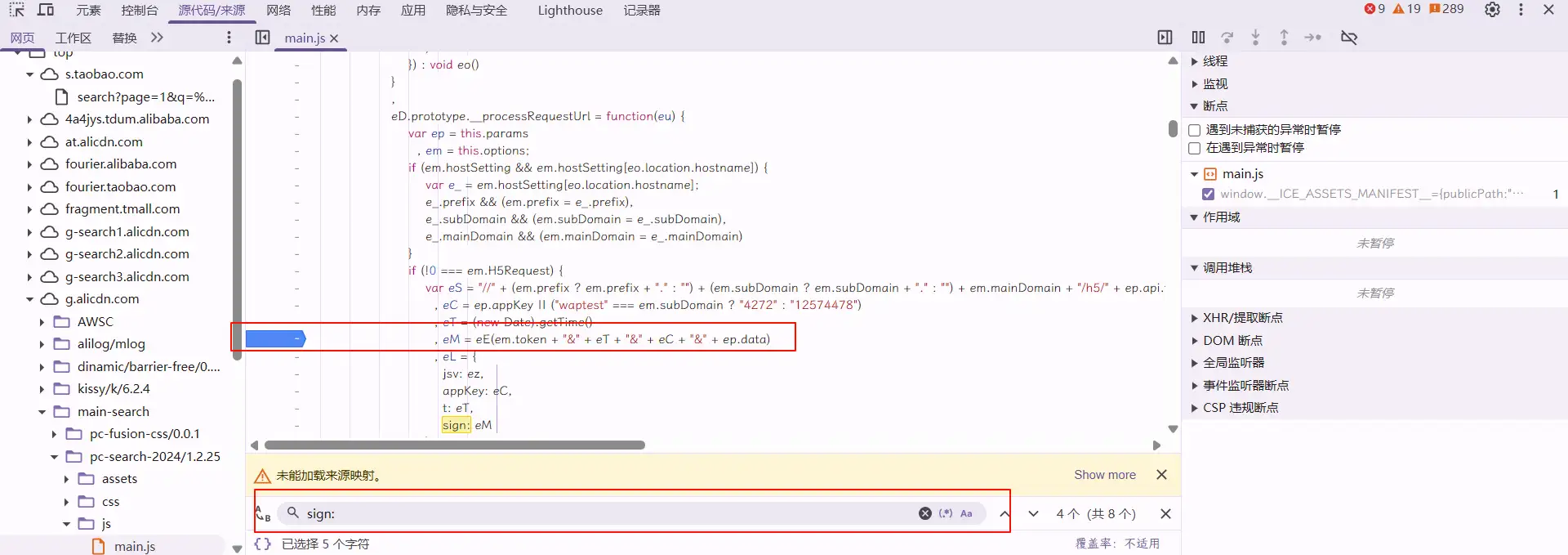 上图蓝色处即为断点也是淘宝
上图蓝色处即为断点也是淘宝